탐색
많은 양의 데이터 중 원하는 데이터를 찾는 과정
대표적인 그래프 탐색 알고리즘으로 DFS, BFS가 있음
스택 자료구조
선입후출(FILO): 먼저 들어온 데이터가 나중에 나가는 자료구조
입구와 출구가 동일한 형태로 스택을 시각화할 수 있음(박스쌓기 - 먼저 쌓은 박스를 가장 마지막에 꺼낼 수 있음)
append() - 삽입
pop() - 삭제
큐 자료구조
선입선출(FIFO): 먼저 들어온 데이터가 먼저 나가는 자료구조
입구와 출구가 모두 뚫려있는 터널로 스택을 시각화 할 수 있음
큐를 구현할 땐 파이썬에서 제공하는 리스트를 사용하는 것보다 deque 라이브러리를 사용하는 것이 더 시간적으로 효율적임!
from collections import deque
# 큐 구현을 위해 deque 라이브러리 사용
queue = deque()
queue.append(5) # 5 삽입
queue.append(2) # 2 삽입
queue.popleft() # 삭제
queue.append(1) # 1 삽입
print(queue) # deque([2,1])
재귀 함수
자기 자신을 다시 호출하는 함수
DFS에서 자주 사용
종료 조건을 제대로 명시해야 함!
def recursive_function(i):
if i == 10:
return
print('재귀')
recursive_function(i+1)
recursive_function(1)
DFS(Depth-First Search)
깊이 우선 탐색이라고 부르며 그래프의 깊은 부분을 우선적으로 탐색하는 알고리즘
스택 자료구조(혹은 재귀 함수)를 이용
1. 탐색 시작 노드를 스택에 삽입하고 방문 처리
2. 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄
3. 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
BFS(Breadth-First Search)
너비 우선 탐색이라고 부르며 그래프에서 가까운 노드부터 우선적으로 탐색하는 알고리즘
큐 자료구조를 이용
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리
2. 큐에서 노드를 꺼낸 뒤에 해당 노드의 인접 노드 중 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리
3. 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
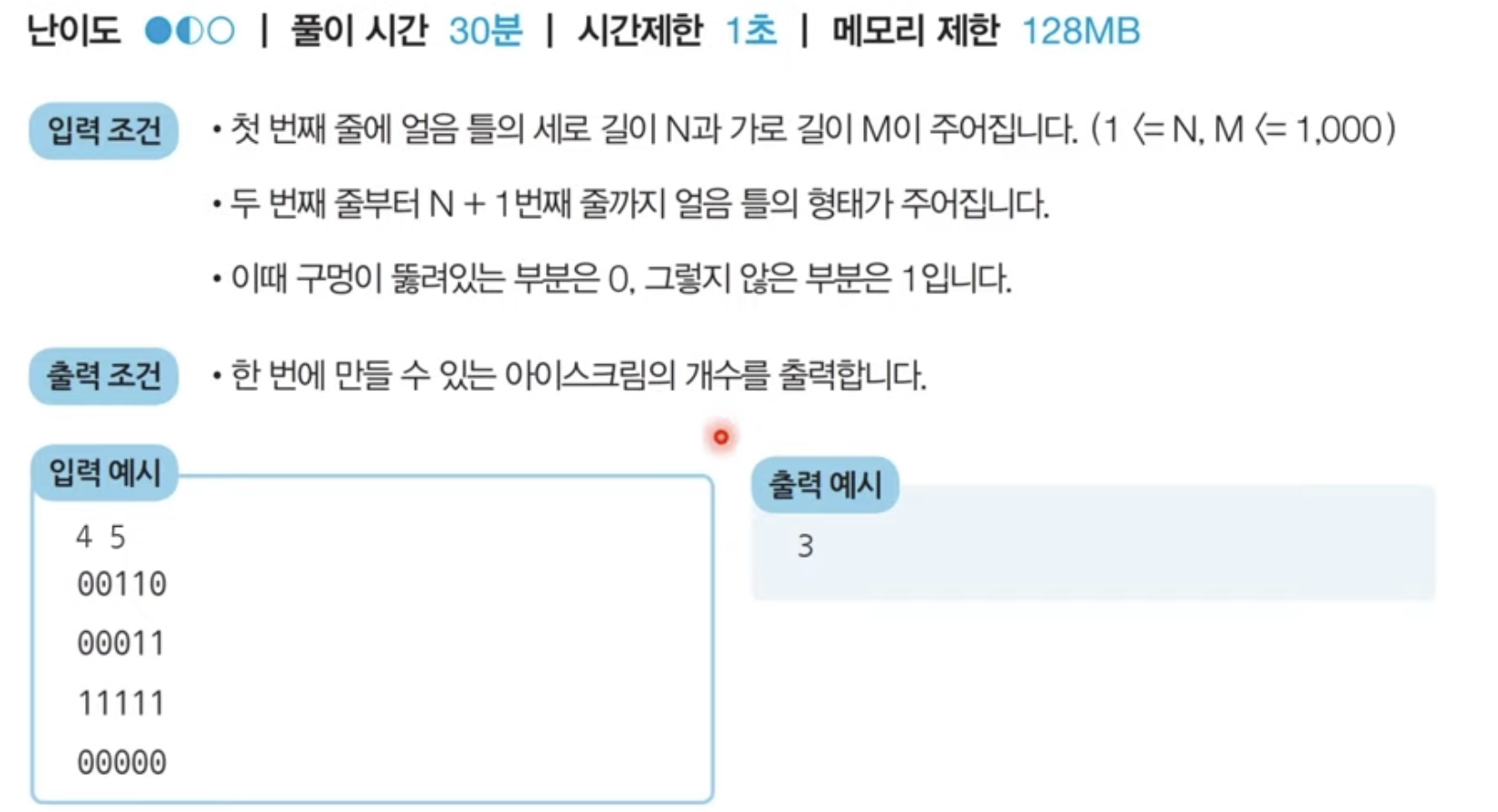
문제 1)
음료수 얼려 먹기

코드
def dfs(x, y):
if x <= -1 or x >= n or y <= -1 or y >= m:
return False
# 현재 노드를 아직 방문하지 않았다면
if graph[x][y] == 0:
# 해당 노드 방문 처리
graph[x][y] = 1
# 상하좌우 위치들 재귀저으로 호출
dfs(x-1,y)
dfs(x, y-1)
dfs(x+1, y)
dfs(x, y+1)
return True
return False
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input())))
# 모든 노드(위치)에 대해 음료수 채우기
result = 0
for i in range(n):
for j in range(m):
# 현재 위치에서 DFS 수행
if dfs(i,j) == True:
result += 1
print(result)
'Algorithm' 카테고리의 다른 글
| 구현(Implementation) (1) | 2023.10.23 |
|---|---|
| 그리디 알고리즘 (1) | 2023.10.22 |